Setup a Calibre Server on VPS
Created on: 15 May 23 14:24 +0700 by Son Nguyen Hoang in English
My journey to create & setup an online book library on Google Cloud VM!
Ebook collecting became my recent hobby for recent months. For most of the time until last week, I simply stored my books in a OneDrive account and managed the books through calibre client. However, some issues on Linux machine caused a small inconvenience in my book database & onedrive synchronicity. Thus, it was a must to come up with a more elegant design that can fulfill my requirements. Although the online library works great at the moment, the actual development & deployment was a very long, complicated process that inflated into many sub-steps and rabbit holes which cost all of my weekends. Hence, I decided to write down all of these steps I took in the hope that this note will be helpful for everyone interested in this topic and me-in-the-future as well.
This small project couldn’t be done without the help of my brother, Linh Vinh Nguyen (https://github.com/nguyenvinhlinh), who was very supportive and guided me through the rabbit hole of DNS, Firewall Rule, NGINX, and more.
Background
- I used Calibre to manage ebook
- The total number of books I owned were 406 books, equivalent to 10 GB of memory.
- I used OneDrive to store book, I paid 44,000 VND each month for an extra 100 GB.
- Calibre pointed to the OneDrive’ ebook folder.
- Becase OneDrive folder was alway synchronized between Window machine, my book database was easily accessed between Window Machine
Motivation & Problem Arise
- I moved back to Linux (duel boot) and installed Linux Mint on my laptop a week ago
- What do I want in my Linux machine? A simple way to view my ebook library? That’s it! However, there is no “OneDrive” official client on Linux.
Of course, some alternatives are available, for example:
-
https://github.com/jstaf/onedriver: A very new tool to sync OneDrive to Linux Machine. This one is fairly new and only downloads files if you need them in the local ends. That’s a huge plus! However, Calibre on Linux cannot open the folder of books located inside onedriver’s synchronized folder.
-
https://github.com/abraunegg/onedrive: Classic tool on Linux. This one however required users to download every file before accessing its. For this repo, Calibre can open the folder book inside the synced folder.
So basically, on Linux machine, I cannot access to my book database except by downloading the folders and re-sync everything before opening calibre on this machine. This is a huge downsize. Especially, when you know that in this machine duel-booted machine, I already had a book folder on the Window-size of the laptop. Keeping another 10 GB of the same folder in one machine was a huge turnoff.
- I figured out calibre can open a content server.
- Also, an open-source repo named
calibre-web(https://github.com/janeczku/calibre-web) was released. I tested it and felt that the UI was so great! - So, how about visiting the books library through calibre-web? This also provides UI to visit the books through mobile phones & tablets!
This suggested me deploy a book content server on a VPS. This content server would work with a book folder that could be synced by abraunegg/onedrive.
Note & Compromise
Here, I had to note one important thing: even though I decided to use calibre-web to view the book, and the server indeed supports the feature to add/edit book, I still want to use my old calibre-client on Window to add/modify book
In addition, calibre database was not supposed to be modified by multiple devices at the same time. Thus, my ideal work scenario/workflow will only support ONE machine to edit/upload/delete book at the same time. In short,** only one device**: calibre client (on Window) or calibre-web server can add/modify/delete a book(s) at one moment. This is an acceptable compromise.
Testing & Prototype
I conducted a test environment to verify the ability of calibre-web to synchronize the books after uploading to onedrive through calibre (client) from Window Machine
- I prepared a book folder in Linux Machine
- I setuped
abraunegg/onedriveto synchronize the folder every 10 seconds by commandonedrive --monitor. Configuration forabraunegg/onedrivecan be found in the official repository. - I started a content server in Linux Machine
From the window machine, I could access the book server at this point. Now, from the Window machine,
- I uploaded a new book
- I deleted a book.
- I turn off the calibre-client from Window Machine
- I waited until the abraunegg/onedrive synchronize the book in Linux machine
- I visit the book server from Window machine
Ideally, when accessing the book server (from Window machine), the new record would have appeared. It didn’t. I encountered one big issue: calibre-web do not automatically reload the server when the database folder is edited by a third party (e.g abraunegg/onedrive). If I turned off the server then restart it manually, the new records showed up normally. This wasn’t the feature I desired! Also, it turned out that the calibre-web server does not provide cli command to restart!
Of course, this required another, more extensive solution to this problem!
Design & Solution: Custom script to start Content Server
What I need now is:
- A program (written in script) to start the book content server and
abraunegg/onedrive - The program runs
abraunegg/onedriveand synchronize the book every X minutes. - Then it can check for the last modified time in the book database.
- If the modified time is different than the last modified time. It manually turns off & on the book server.
Fortunately, the python library supports a library to run another program and fetch output. The library/module is called subprocess
In reality, the module was implemented like this
import subprocess
def kill_process_at_port(portnumber):
string_port = str(portnumber) + "/tcp"
subprocess.call(["fuser", "-k", string_port])
# example: execute(["onedrive", "--synchronize"])
def execute(cmd):
popen = subprocess.Popen(cmd, stdout=subprocess.PIPE, universal_newlines=True)
for stdout_line in iter(popen.stdout.readline, ""):
yield stdout_line
popen.stdout.close()
return_code = popen.wait()
if return_code:
raise subprocess.CalledProcessError(return_code, cmd)
Ideally, we need to get the output from abraunegg/onedrive to check when the synchronization is finished. When the process finishes, we check the modified date of the metadata.db file (located in the book folder) to determine if the web-server needs to restart or not.
This whole step was repeated every X minutes. This was scheduled used by sched module. In practice, the code (main) looks like this. Note that Utils, onedrive_server, calibre_server & default_config are my customed built python class.
import time;
import sched, time
# Init config steps ...
print("Start, clear process at port " + str(default_config.PortCalibreWeb));
kill_process_at_port(default_config.PortCalibreWeb)
my_utils = Utils(default_config);
my_calibre_server = calibre_server(util = my_utils, config=default_config)
my_onedrive_server = onedrive_server(util= my_utils,config= default_config, calibre_server=my_calibre_server)
def main(schedule):
def schedule_next_process():
my_utils.close_log();
schedule.enter(default_config.TimeCheckOneDriveSecond, 1, main, (schedule,));
if (default_config.Log == True):
my_utils.open_log();
my_calibre_server.start_server();
my_onedrive_server.call_onedrive(onFinish=schedule_next_process)
my_scheduler = sched.scheduler(time.time, time.sleep)
my_scheduler.daemonic = False
my_scheduler.enter(default_config.TimeCheckOneDriveSecond, 1, main, (my_scheduler,))
my_scheduler.run()
In practice, this whole program will be run as a systemctl service. However, sched cannot work in systemctl with scheduler.daemonic == True. You MUST set .daemonic to False, otherwise the progress will crash. See my code above. The solution was from stackoverflow, here is the original link:
https://stackoverflow.com/questions/5835600/apscheduler-not-starting
So, as far as the test went, I was rest assured that the program worked fine on a local Linux machine. The book now appeared on the web server correctly after new ones were added from Window’s calibre client.
Then, we move to the interesting part: VPS Deployment
Google Cloud VM as a VPS: Startup
Why I choose Google Cloud?
- Because they give me free 300 USD into the credits account!
- My VM cost (estimated) 8 USD per month. That means I have free 3 years of using it!
My VM was very lightweight, here is the setup:
- OS: Ubuntu 20.04 (x84/64)
- Ram: 1 GB
- Memory: 20 GB
You can create one by visiting Google Cloud’ VM Machine:
Connecting to the VM was deadly simple. The cloud had a builtin ssh viewer to connect to the VM directly through the browser. Also, they had preinstalled python and git. So lovely! Isn’t it?
On the VM, install pip, abraunegg/onedrive, calibre-web through pip .
sudo apt install python3-pip
pip install calibre-web
I also clone & pull my custom program into the machine as well.
For onedrive you are advised to visit the official repo site and check for the instruction. In my case, I used the guide for Ubuntu 20.04
To reduce the download size & check time for each sync, you also should visit abraunegg/onedrive instruction guide to limit the sync folder to a particular book folder only. This is done by manually setup a sync_list. Visit the official repo guide here to apply for your case. What you need is sync_list file located in the ~/.config/onedrive/ folder. In the sync_list file, list the folder you particularly want to sync. From now on, the onedrive only sync the folders in this list. Here is my sync_list:
# sync_list
/MyLibrary/* #folder name
For more detail, visit the link: https://github.com/abraunegg/onedrive/blob/master/docs/USAGE.md#performing-a-selective-sync-via-sync_list-file
Then you setup a .service file to run the custom program as a service in systemctl. I made this file from my Linux machine and pushed it into Git as well. So that when I cloned the repo, I got the file in VM already. I named it calibre-automate.service
[Unit]
Description=My book service
After=multi-user.target
[Service]
Type=simple
Restart=always
ExecStart=/usr/bin/python3 /home/[my user name]/[my customed program folder]/main.py
User=[user name on VM machine]
[Install]
WantedBy=multi-user.target
If you have the .service file, then move it to the systemd folder by command:
sudo mv nano /lib/systemd/system/calibre-automate.service
Then use below command to enable/start/stop the service.
sudo systemctl enable malibre-automate.service
sudo systemctl enable alibre-automate.service
sudo systemctl stop alibre-automate.service
The simple setup was finished. However, you still cannot access this server, even if it is running. This is because you have not setup Google Cloud static IP & Firewall
Google Cloud VM as a VPS: Setup VPC
You may have a VM and a working server working, but you don’t have static ip to open this VM to the world, roughly speaking. To do this, what you need is
- Reserve an external static IP and assign it to your VM
- Setup firewall rule for that IP
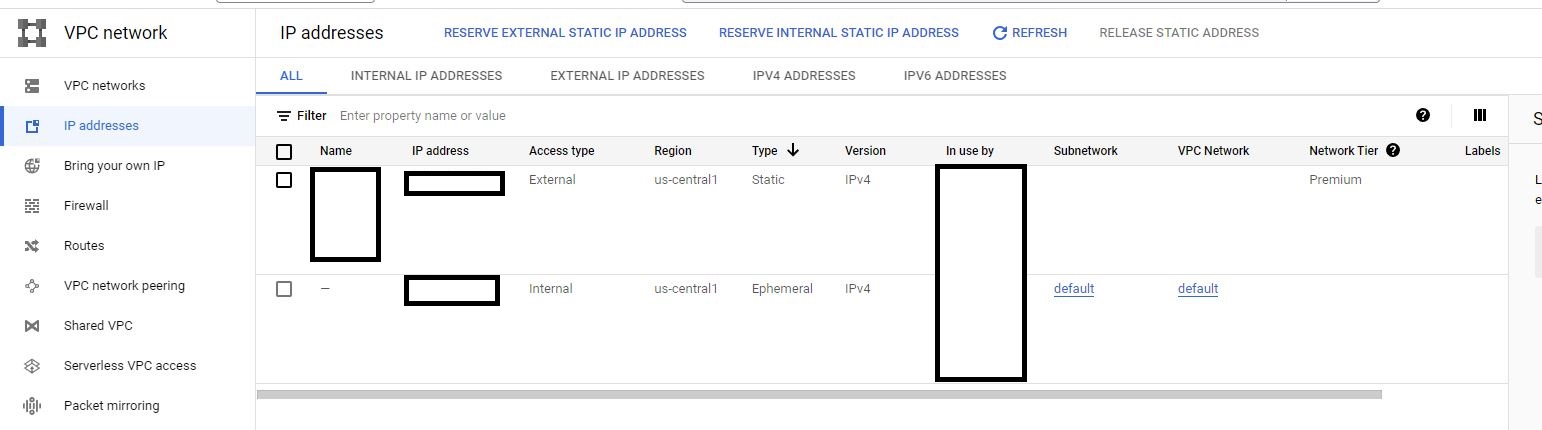
These two steps can be done in Google Cloud VPC.
Reserving an external static IP
To reserve a static IP, hit Reserve External Static Ip Address and then do the setup in the next popup.
Normally, the setup will suggest you attach this IP to an instance VM machine that you just created. If so, link it to your created VM. If not, go to your VM -> Edit -> Find Network Interface section, the option to add external ip-v4 address should be shown here for you to choose the static IP you reserved (your choice).
Note that reserving static IP is not free!
Setup firewall rule
By default, incoming traffic to your VM is forbidden. To overcome this, you must make a new firewall rule from VPC. In my case, I set up a rule that allows all IPs to enter my port 8083 (where my calibre-web server works!).
Normally, you can selectively choose which instance VN will use which rule by setup the targets on the firewall rule. However, in my case, I applied the rule to all instances in the network. After all, there is only one instance in my network.
After these above steps are completed, assume that your external IP address was X.X.X.X, and the port where your calibre-web server works is 8083. You now can visit the VPS from everywhere in the world by visiting
X.X.X.X:8083 from the browser.
Creating & Linking VM to a subdomain (Optional)
My domain name (2023) was sonnguyen9800.com. In addition, I want to create a subdomain called mylibrary.sonnguyen9800.com and allow direct to the calibre-web server without manually entering the ip & port. How can I do that?
My domain was bought and managed in hostinger. Thus, I visited the dns manager and add an A record like below. In the content part, just fill in the external IP X.X.X.X.
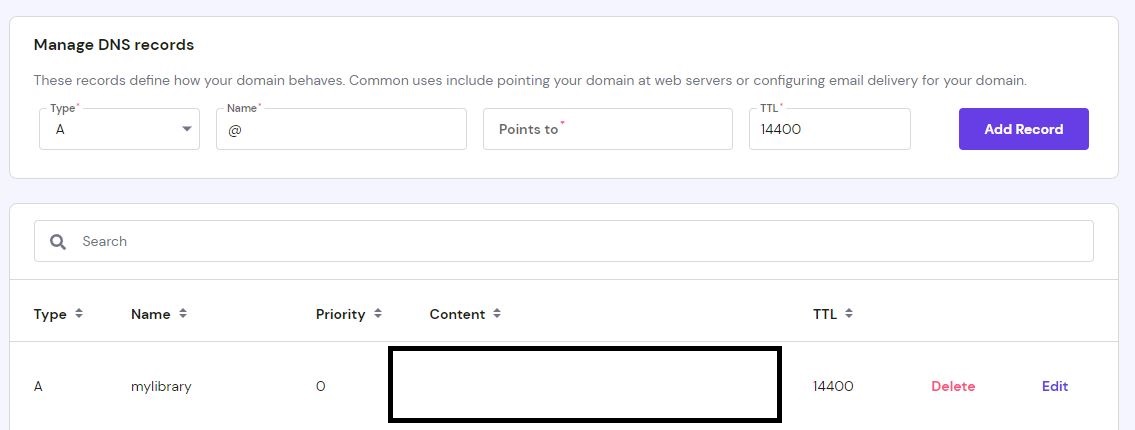
Here are some notes while setup the subdomain:
- The record must be
Atype, I tested onCNAMEbut it didn’t work. - Some keywords cannot be used in the
namesection. For example, my original subdomain name waslibrary.sonnguyen9800.combut this didn’t work. Hence, I renamed it tomylibrary.sonnguyen9800.comand it worked pretty well. The change was updated almost instantly. - In my first attempt, my subdomain was
sub.sonnguyen9800.comand it worked. I deleted its but after 1 or 2 hours I can still access it, even though it had been removed from thednn recordslist. This means that record deletion may take longer wait than adding a new record.
After setup the subdomain, I can visit the calibre-web server through the domain mylibrary.sonnguyen9800.com:8083.
Routing default port by NGINX (Optional)
But it is still not enough! I don’t want to type the PORT NUMBER (8083) every time visit the site. By default, every access to the IP was routed to port 80. So what I want is to automatic routing the incoming request to port 80 to be forwarded to my calibre-web server’s port 8083
First, you must install nginx. Run sudo apt-get install nginx to install the software.
Create a nginx .conf file. You may want to make it from your main computer/laptop in the same project repo and pull it to your VM along with other files. In my case, I name the file calibre-server.conf
server {
listen 80;
server_name mylibrary.sonnguyen9800.com
location / {
proxy_set_header host $host;
proxy_pass http://127.0.0.1:8083;
proxy_redirect off;
}
}
Put this file into /etc/nginx/sites-available/. Then use systemctl to start nginx service. Now, you can visit the web server directly through mylibrary.sonnguyen9800.com. Here is the result!
In reality, I added a button from my main website and visit the library through that subdomain name.
Increase max size for client request in NGINX (Update 20th of May, 2023)
This library web app provides features to upload book. Normally, my books’s size are not small and can be as large as 100 Mb (comic ebook)
By default, nginx prevent files larger than a certain amount (e.g 2Mb). To modify this, go to the file:
/etc/nginx/nginx.conf
add the line client_max_body_size XM; in the http section. In the code, “X” is the maximum body size of client request you want to set (mine is 100 Mb so I set the line to be client_max_body_size 100M).
Then save the file then run systemctl reload nginx.service.
Run the above commands in sudo if needed.
Prevent google from indexing my library by NGINX (Update 29th of May, 2023)
Google robot sometime does site-crawling and begun indexing my library, which is supposed to be private. To fix this, what I did was add the X-Robot header to the request return from nginx.
To do this, visit calibre-server.conf - this is the config file you created earlier, then add the header in the server tag
server {
listen 80;
server_name mylibrary.sonnguyen9800.com
location / {
proxy_set_header host $host;
proxy_pass http://127.0.0.1:8083;
proxy_redirect off;
}
add_header X-Robots-Tag "noindex, nofollow, nosnippet, noarchive"; // <--- This line is added
}
From now on, the google crawler no longer can do indexing on my library. We can also test the header work by visit https://toolsaday.com/seo/x-robots-tag-checker to verify the X-Robots-Tag.
Next Process: SSL & HTTPS (to be updated!)
- The site
mylibrary.sonnguyen9800.comdid not supporthttpsyet! Thus, visiting the site throughhttps://mylibrary.sonnguyen9800.comwill cause problems. - This issue will be addressed in the future.
Study Notes:
There are a lot to learn after this small-but-complicated project:
- There are significant gaps between development & deployment
- Web configuration is very complicated. Cloud services such that AWS Beanstalk / Netlify / Heroku were born to ease this issue. However, the trade off is that the developers may lack basic knowledge about these setups & configs if they relies too much on these services.
- Having your own VPS is actually so good!
Update 2 - 5 2024:
- The sever run pretty well, with only one time it had issue. The issue is simply because the disk size of the VM reached limit. To solve, i simply purchase more space from Google.
- I am still confused about the billing policy of Google, sometime they don’t charge me, sometime they do. In monthes that they require payment, the cost is about 70k (VND) - less than 3 USD.
- To save cost & because I have my own homeserver already (see my other post on Immich homeserver), I no longer use Google Cloud VM.